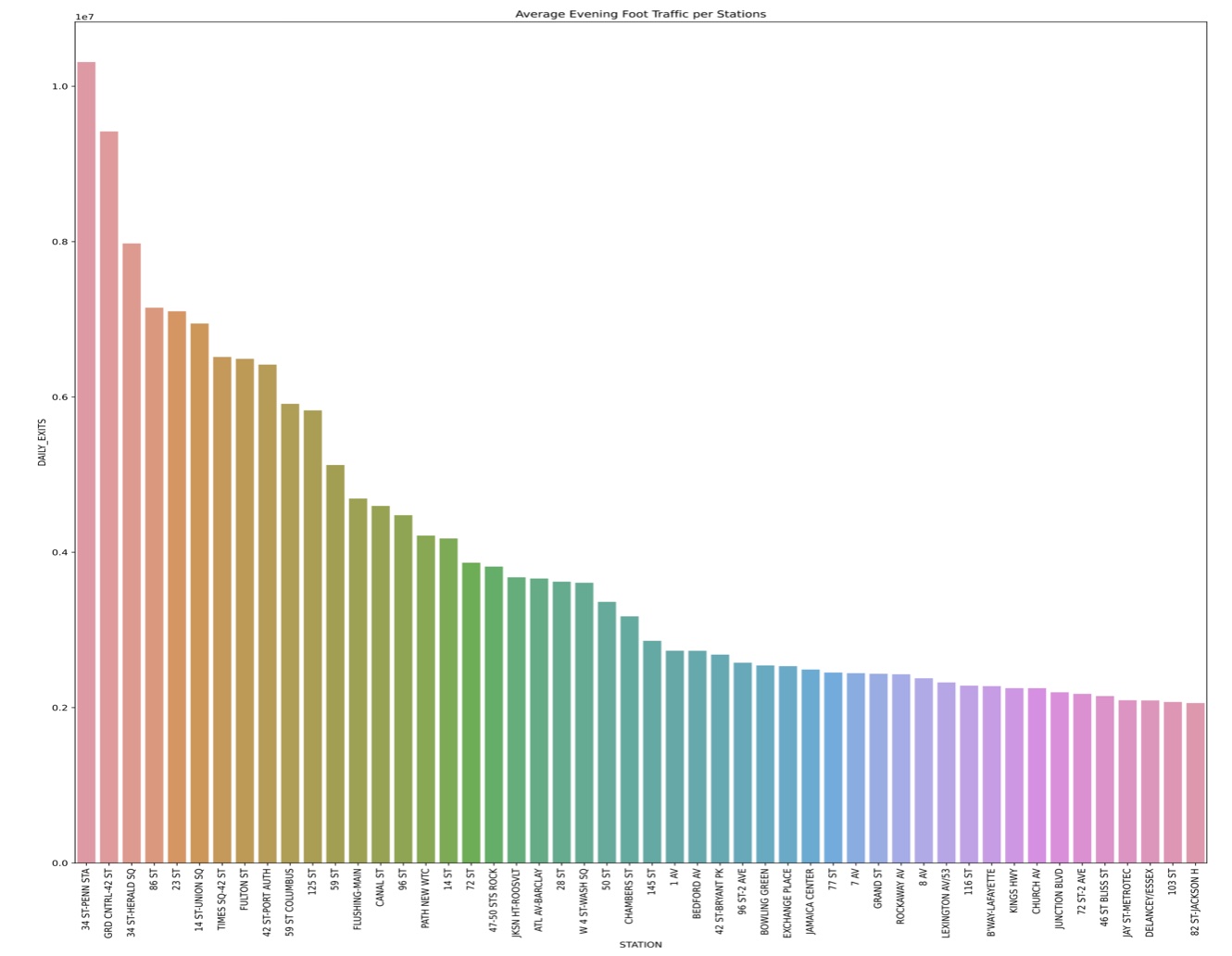
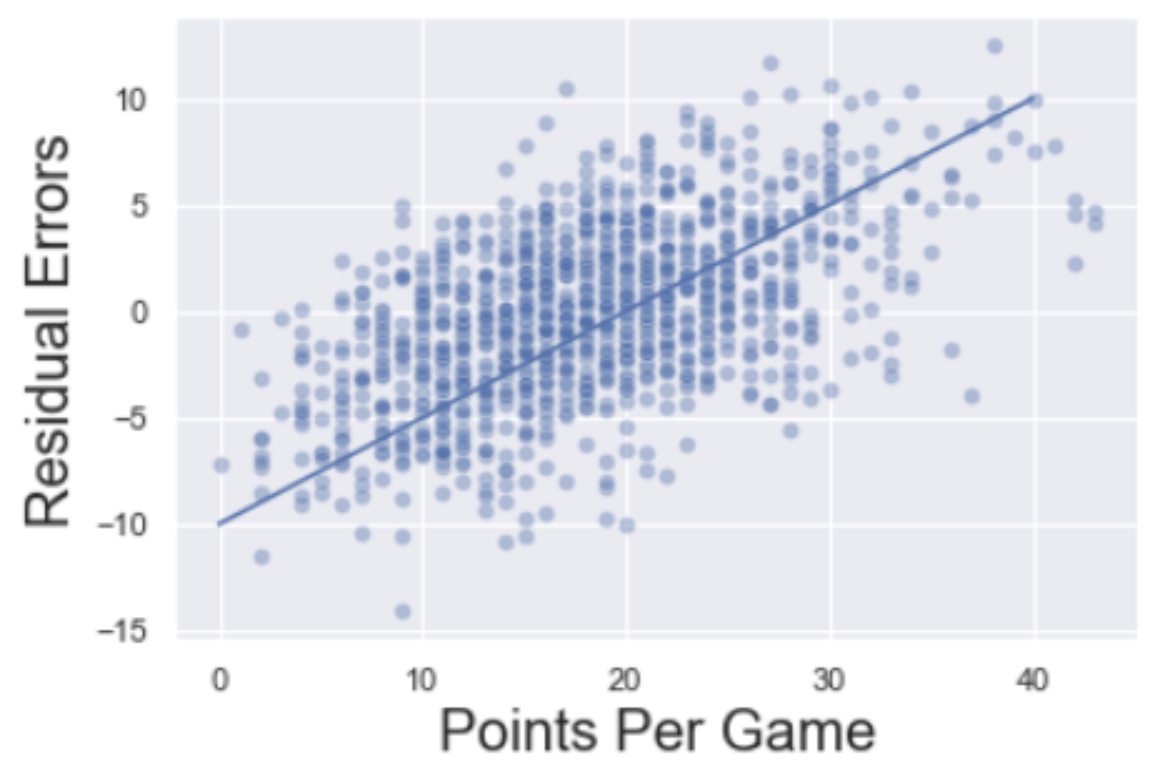
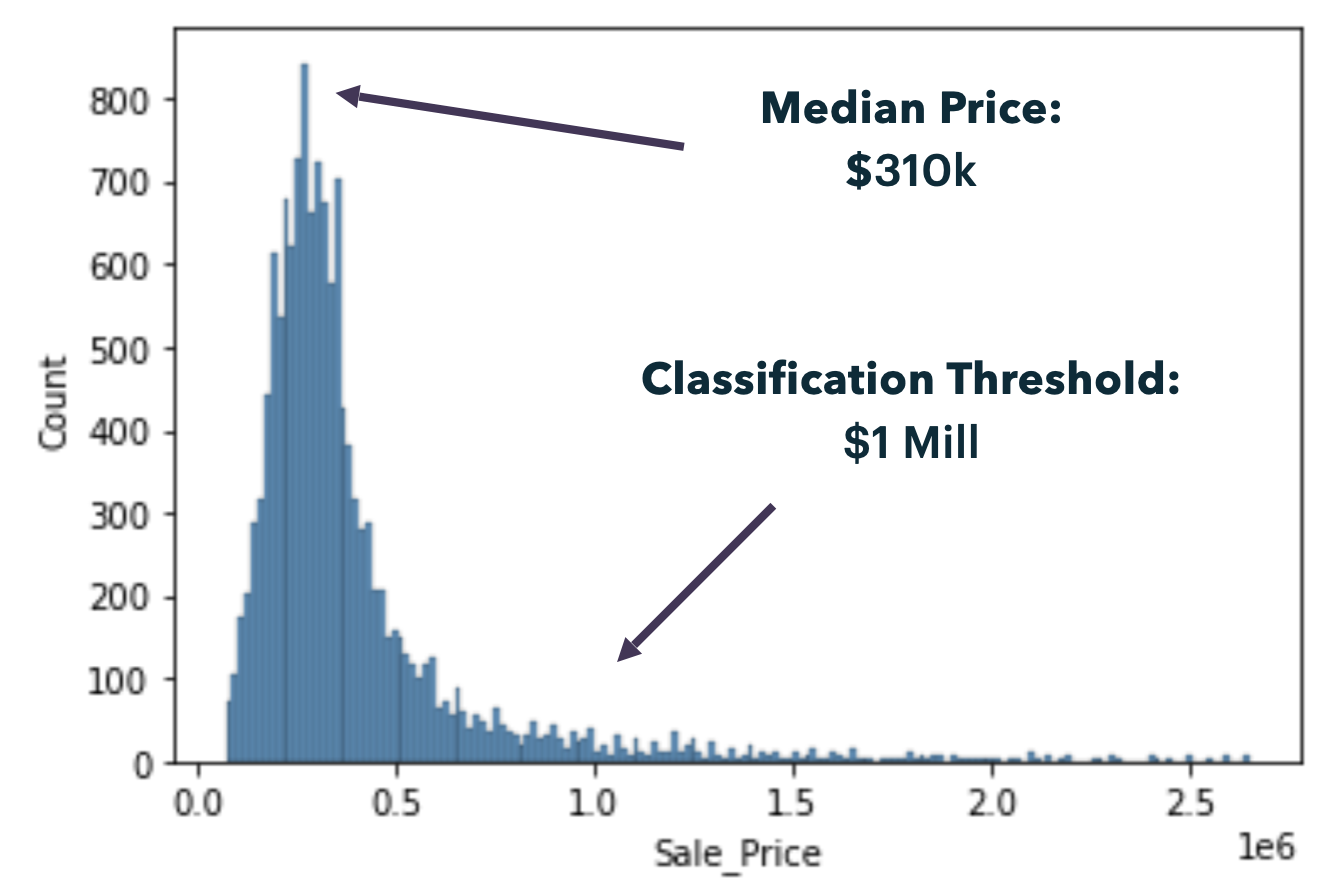
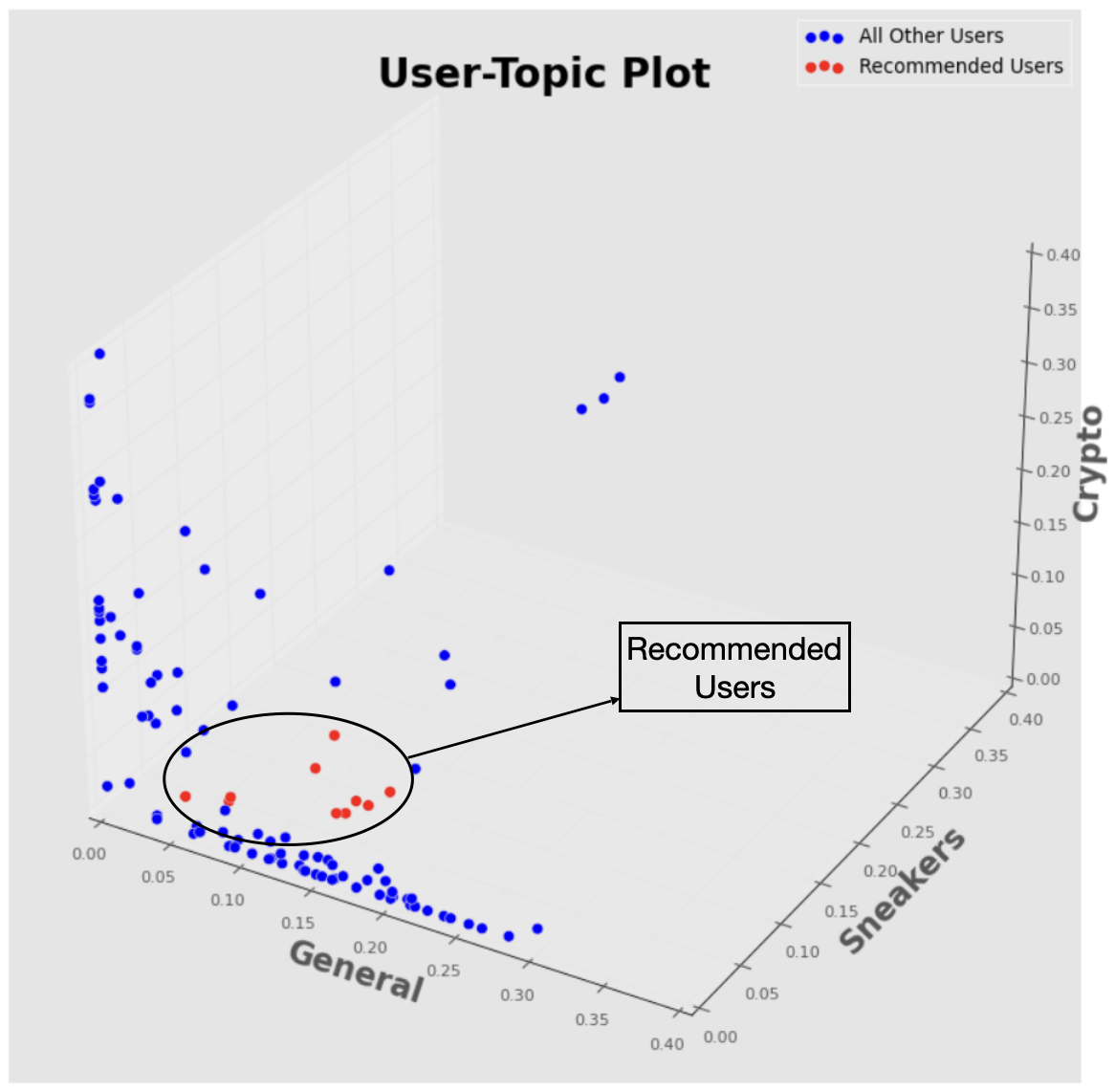
Hi there 👋🏻
Welcome to my website! My name is Avery, and I’m fascinated by the world of information. My goal is to use data to better understand ourselves and generate insights that add value to society. From predicting future trends to uncovering hidden correlations, my work strives to make sense of the chaos, offering a fresh perspective on the world around us. Feel free to check out my work below!