- The project aimed to build a recommendation model to suggest 2nd degree Twitter users to follow based on collective tweets, retweets, and likes.
- Approximately 19,700 tweets from 106 different Twitter accounts were scraped using Twitter’s Tweepy API.
- Natural language processing, topic modeling, and distance calculations were used to determine the top 10 most similar accounts based on the user’s Twitter preferences.
- The project began by collecting up to 100 tweets/retweets and 100 likes per user, compiling the data into a data frame, and cleaning the data.
- The data cleaning process involved stripping punctuation, removing HTML links, converting characters to lowercase, and removing certain parts of speech.
- A function was created to extract crypto-specific terms, and all 200 tweets per user were consolidated into one document, resulting in 106 final documents for topic modeling.
- SciKit Learn’s CountVectorizer and TF-IDF Vectorizers were used to convert each term in the document to a numerical value.
- Latent Semantic Analysis (LSA), Non-Negative Matrix Factorization (NMF), and Latent Dirichlet Allocation (LDA) were applied to compile all terms into 3-5 main topics, reducing dimensionality.
- The NMF model was chosen as it correctly categorized the two most relevant topics of interest — crypto and sneakers.
- The cosine-similarity function was implemented to compare the user’s personal account’s topic values with all other 105 documents to determine the most similar accounts based on the user’s tweets and likes.
Project 4: Twitter Recommendation Alogorithm
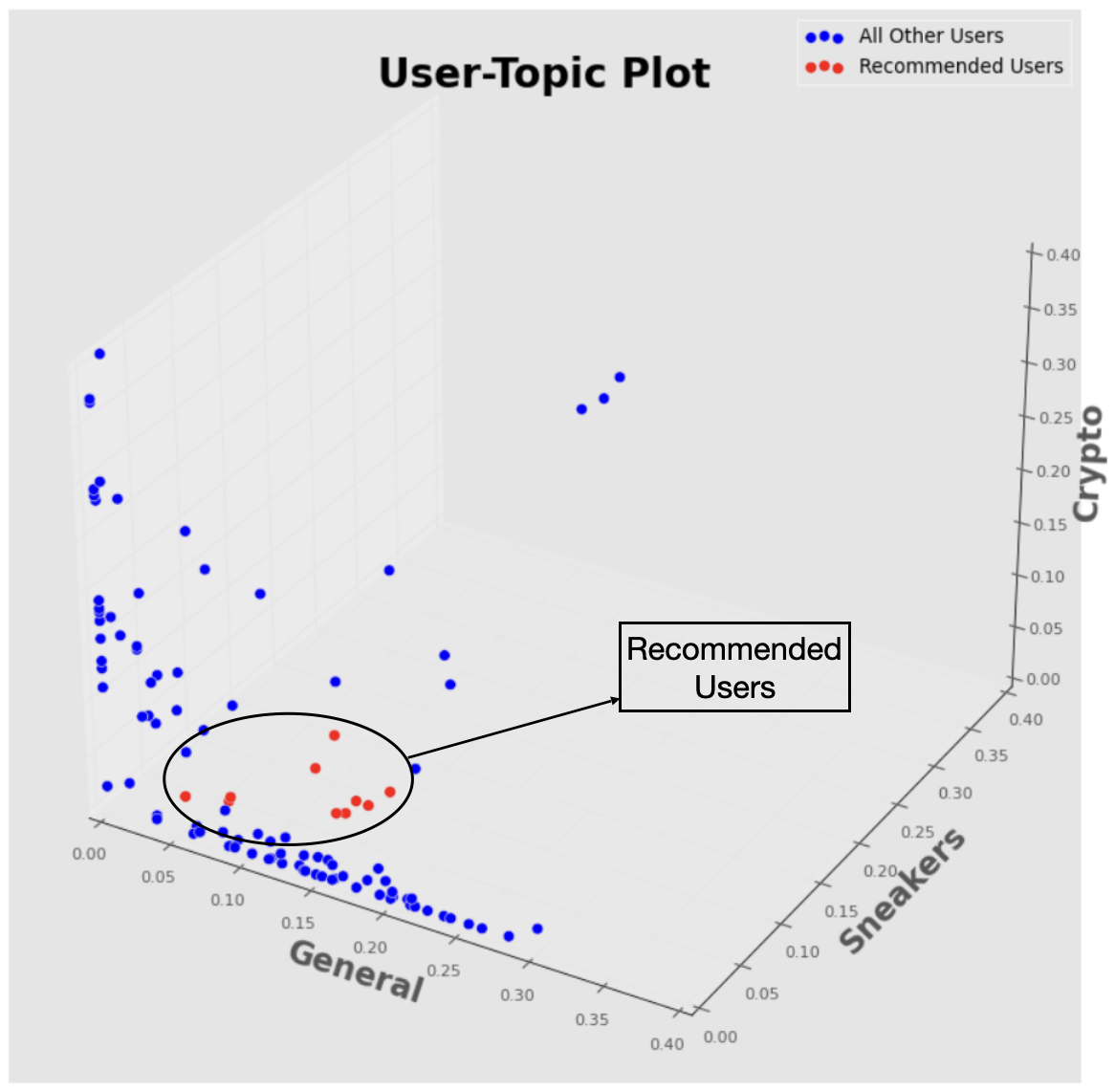
A graphic representing the cluster of accounts most similar to my own based on three different topics: Crypto, Sneakers, and General