- The project aimed to create a classification model to help a Miami real estate agency improve its client management process by distinguishing high-valued clients from normal clients.
- The agency wanted to restructure their service to provide better-skilled agents and improved customer experience for high-valued clients, defined as those with property values above $1 million.
- The classification model was designed to predict whether a potential client would be high-valued or normal based on the property’s features.
- The data for the project came from Kaggle’s Miami Housing dataset, which included 13,932 single-family homes sold in Miami in 2016.
- Each entry in the dataset represented a single sale and included numeric features such as sales price, land square footage, distance from the ocean, age, structural quality, etc.
- A binary feature was added to indicate whether a home value was above or below $1 million, which served as the target feature for the classification model.
- The data included 13,932 sale entries with 17 features, with the target feature (sales greater than $1 million) representing a minority of 5.12% of the entire dataset.
- The minority target data was upsampled three times its original amount to rebalance the data, now representing a 16% minority.
- K-Nearest Neighbors, Logistic Regression, and Random Forest were chosen as base models, with Random Forest selected as the final model due to its simplicity, interpretability, and feature importance tool.
- The data was split into training, validation, and test sets (60%, 20%, 20% respectively), and the F1 score was used as the evaluation metric. The Random Forest model produced the highest initial F1 score, which was further improved by tuning hyperparameters and dropping insignificant features.
Project 3: Classification Model for Miami Real Estate Market
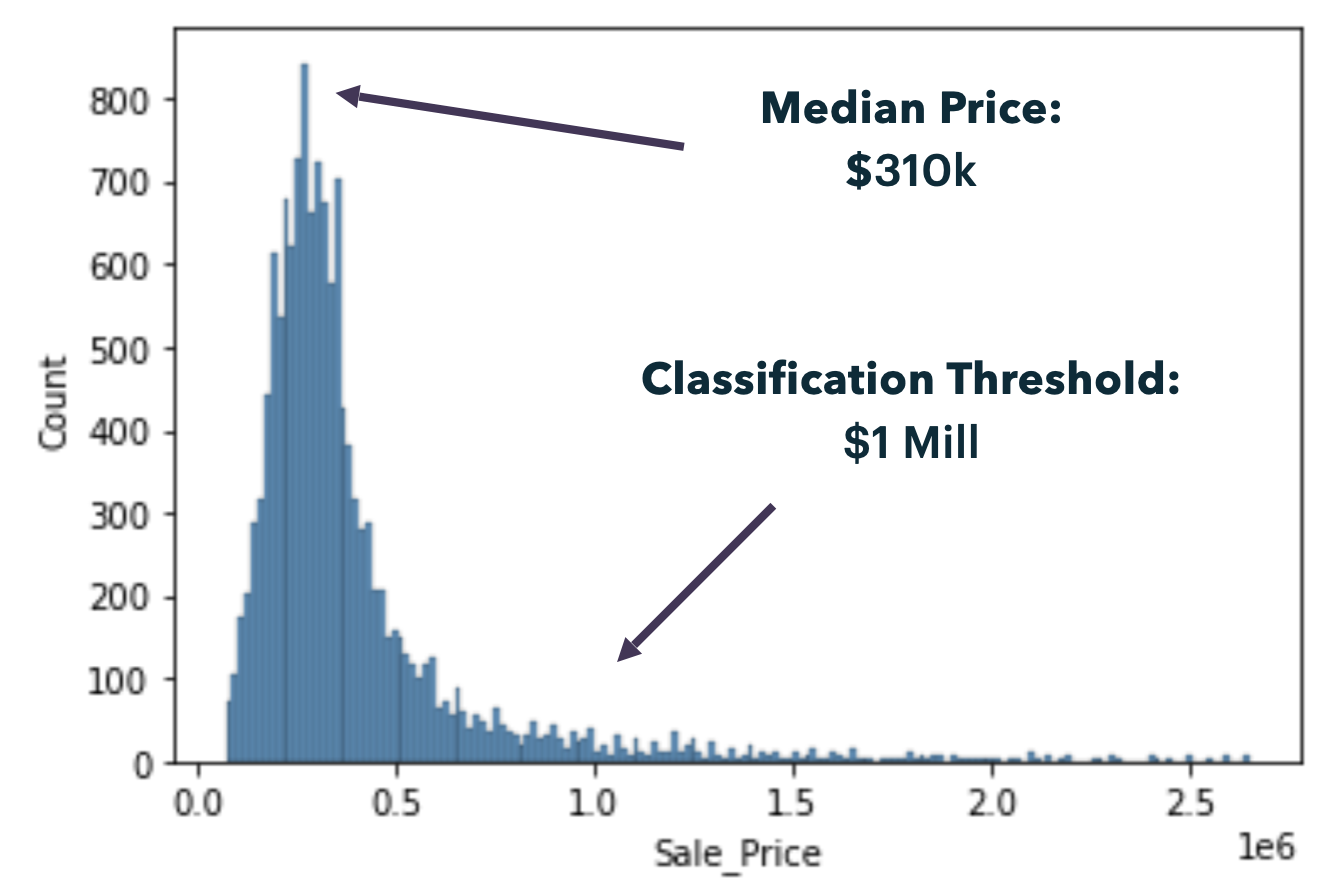
A graphic outlining the distribution of Miami housing prices.